在上篇 「Day22 淬鍊之章-多檔案上傳 ETL 流程-實作篇2」 中,我們完成了完整的檔案檢查與 ETL 排程機制。
不過在實務中,難免會出現這些情況:
這時,我們就需要一個關鍵能力 —— Backfill(資料補跑機制)。
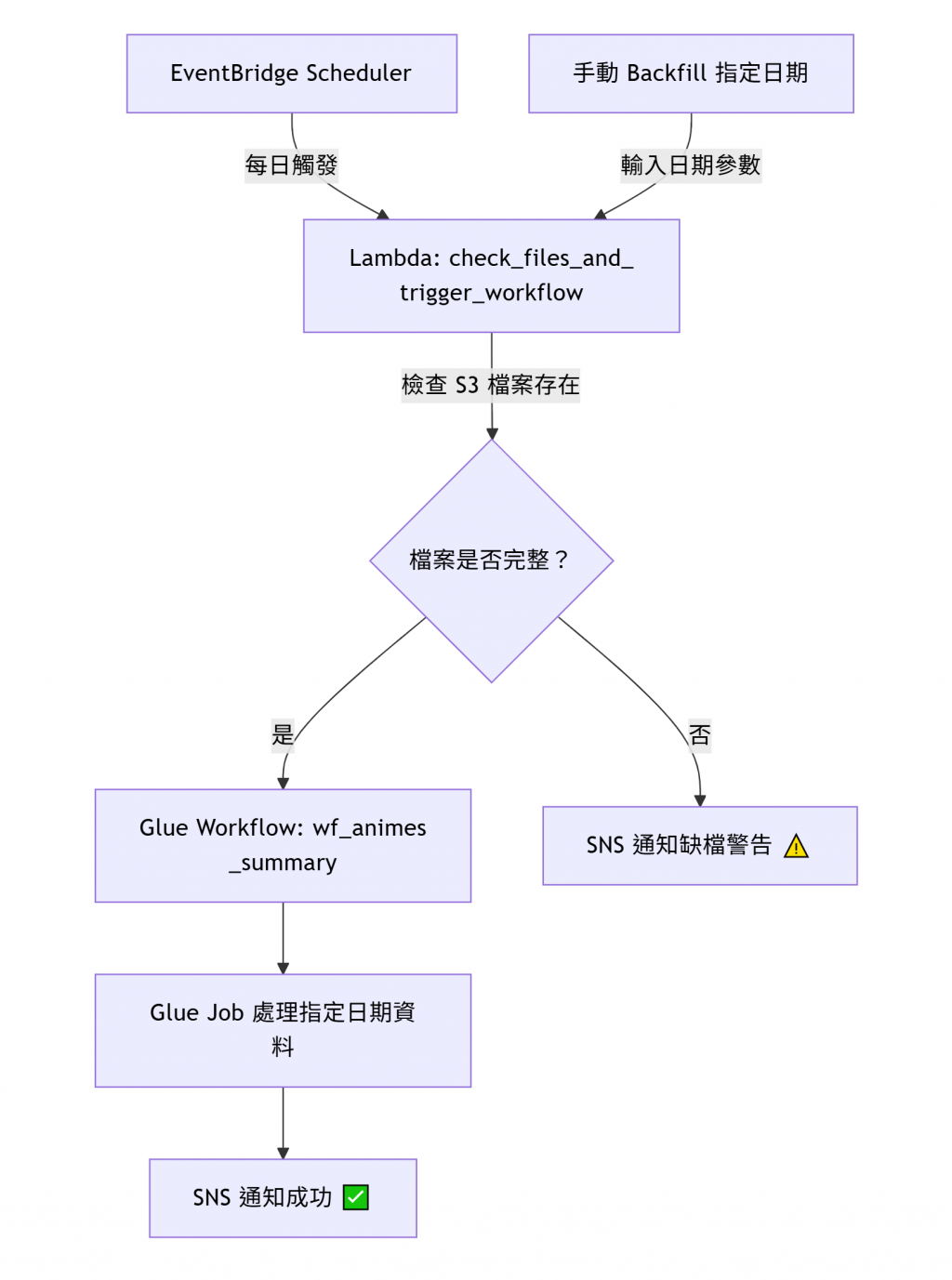
今天我們將擴充原本的 Lambda,讓它除了每天自動偵測「今日檔案」外,也能手動指定任意日期重新檢查與觸發 Glue Workflow,進一步提升整個 Data Lakehouse Pipeline 的 可重入性(Idempotent)與可恢復性(Recoverable)。
再調整一次 Lambda Function 使其可以做到以下內容:
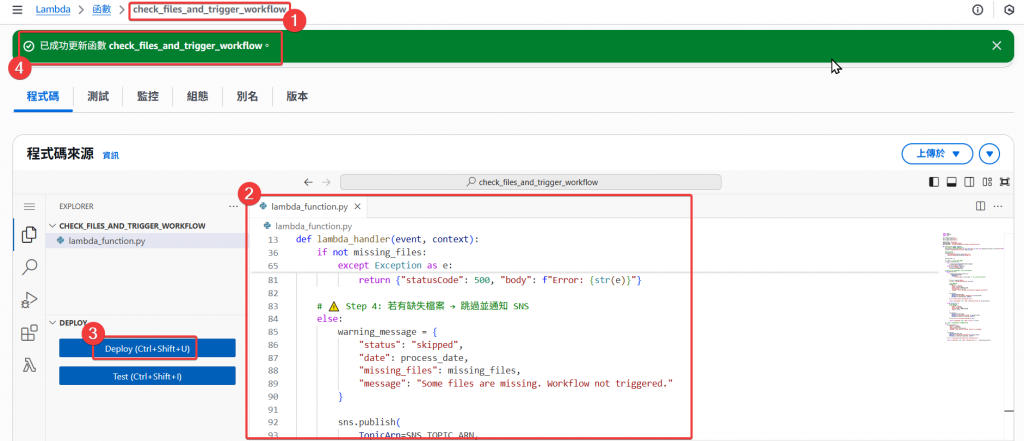
修改程式碼:
注意要改成自己的 account_id
import boto3
import datetime
import json
s3 = boto3.client("s3")
glue = boto3.client("glue")
sns = boto3.client("sns")
BUCKET_NAME = "anime-lake"
WORKFLOW_NAME = "wf_animes_summary"
SNS_TOPIC_ARN = "arn:aws:sns:ap-east-2:064083567781:anime-etl-alert"
def lambda_handler(event, context):
# 🗓️ Step 1: 取得日期(預設今天)
process_date = event.get("date") if event and "date" in event else datetime.date.today().strftime("%Y-%m-%d")
print(f"🔍 Checking files for date: {process_date}")
# 預期檔案位置
expected_files = [
f"Bronze/animes/{process_date}/animes.csv",
f"Bronze/ratings/{process_date}/ratings.csv"
]
missing_files = []
# 🔎 Step 2: 檢查 S3 檔案是否存在
for key in expected_files:
try:
s3.head_object(Bucket=BUCKET_NAME, Key=key)
print(f"✅ Found: {key}")
except s3.exceptions.ClientError:
print(f"❌ Missing: {key}")
missing_files.append(key)
# ✅ Step 3: 若所有檔案皆存在 → 觸發 Glue Workflow
if not missing_files:
try:
response = glue.start_workflow_run(
Name=WORKFLOW_NAME,
RunProperties={
"process_date": process_date
}
)
run_id = response["RunId"]
print(f"🚀 Started Glue Workflow: {run_id}")
# SNS 成功通知
message = {
"status": "success",
"date": process_date,
"workflow_name": WORKFLOW_NAME,
"workflow_run_id": run_id,
"message": "All files found, Glue Workflow triggered successfully."
}
sns.publish(
TopicArn=SNS_TOPIC_ARN,
Subject=f"✅ Glue Workflow Triggered for {process_date}",
Message=json.dumps(message, indent=2)
)
print("📨 SNS success notification sent.")
return {"statusCode": 200, "body": f"Workflow started for {process_date}"}
except Exception as e:
# SNS 失敗通知
error_message = {
"status": "failed",
"date": process_date,
"workflow_name": WORKFLOW_NAME,
"error": str(e)
}
sns.publish(
TopicArn=SNS_TOPIC_ARN,
Subject=f"❌ Glue Workflow Failed for {process_date}",
Message=json.dumps(error_message, indent=2)
)
print(f"🛑 Error starting Glue Workflow: {e}")
return {"statusCode": 500, "body": f"Error: {str(e)}"}
# ⚠️ Step 4: 若有缺失檔案 → 跳過並通知 SNS
else:
warning_message = {
"status": "skipped",
"date": process_date,
"missing_files": missing_files,
"message": "Some files are missing. Workflow not triggered."
}
sns.publish(
TopicArn=SNS_TOPIC_ARN,
Subject=f"⚠️ Missing Files Detected for {process_date}",
Message=json.dumps(warning_message, indent=2)
)
print("⚠️ SNS warning notification sent (missing files).")
return {"statusCode": 200, "body": f"Missing files: {', '.join(missing_files)}"}
由 EventBridge Scheduler 自動觸發:
{}
Lambda 會自動檢查「今日」日期的檔案。
執行測試
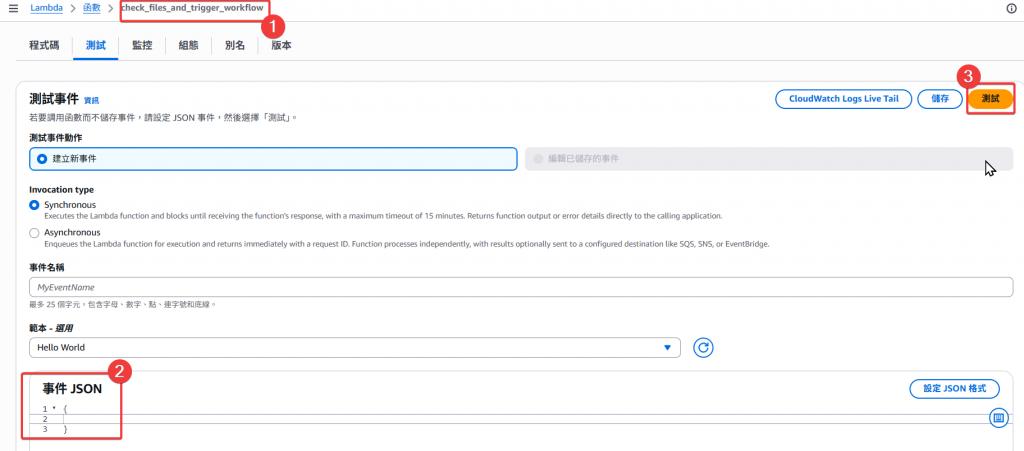
當 json = {} 時,會自動帶入當日日期
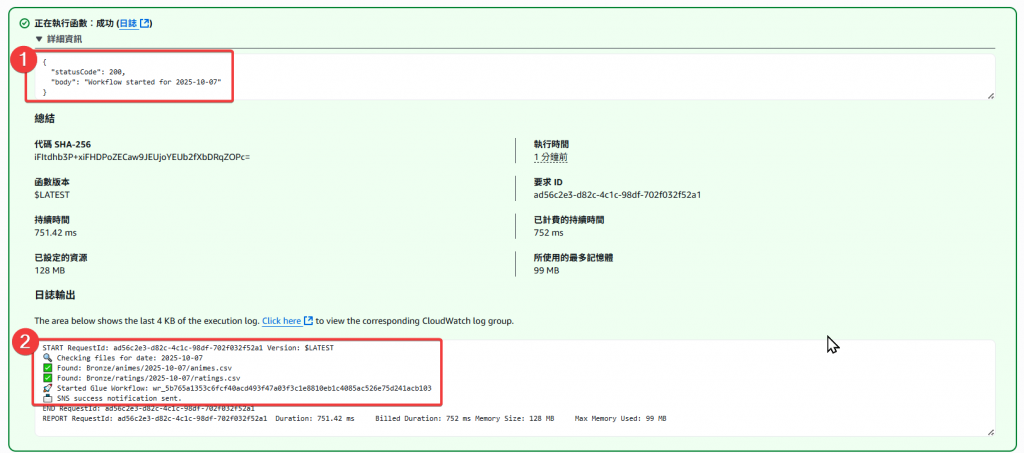
接著確認 Glue Job 有正常被觸發

手動呼叫 Lambda(例如在 Console 或 CLI 中):
{
"date": "2025-10-06"
}
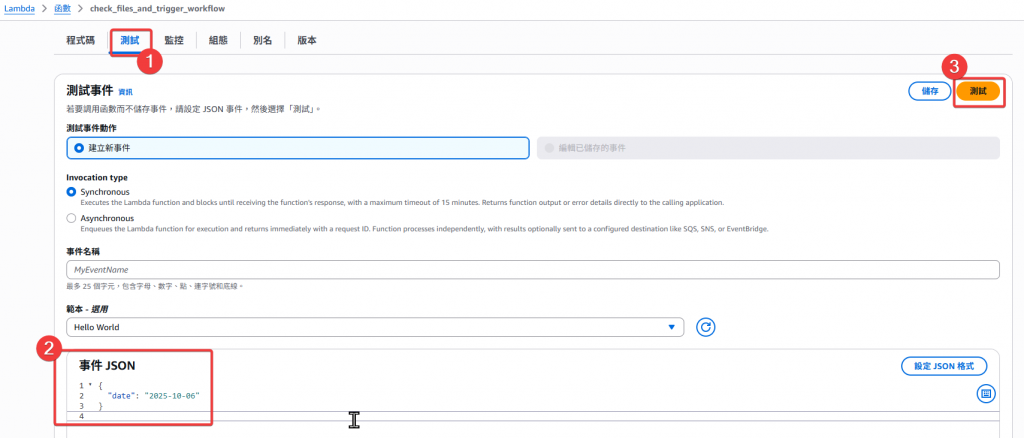
這樣會檢查:
s3://anime-lake/Bronze/animes/2025-10-06/animes.csv
s3://anime-lake/Bronze/ratings/2025-10-06/ratings.csv
若都存在,就會自動觸發 Glue Workflow 並帶入參數:
--process_date=2025-10-06
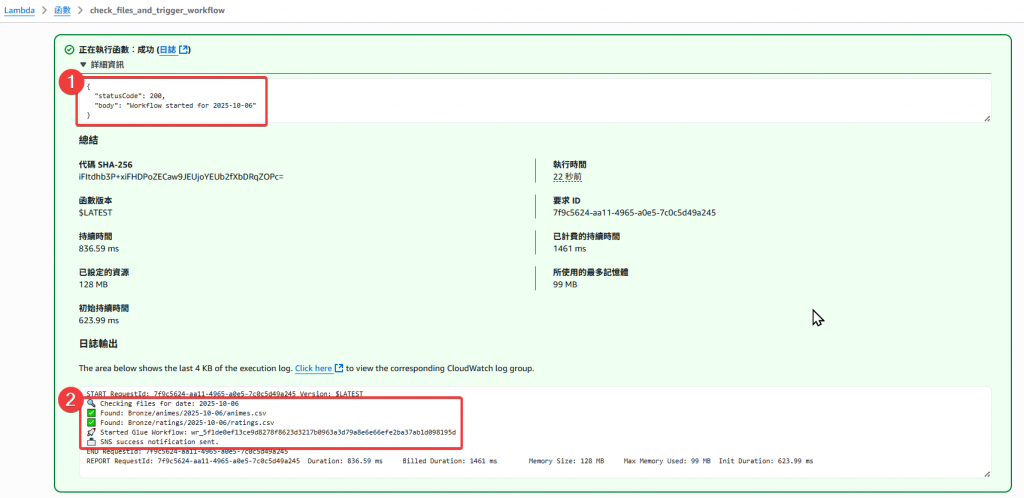
接著確認 Glue Job 有正常被觸發

| 功能模組 | 說明 | 實作方式 |
|---|---|---|
| 日期輸入 | 可自動/手動指定處理日期 | Lambda event 參數 |
| 資料驗證 | 確保當天所有檔案都存在 | s3.head_object |
| 參數化設計 | Glue Job 接收 --process_date |
支援分區處理與補跑 |
透過這次的 Backfill 實作,我們讓 ETL Pipeline:
使用 Lambda + Glue Workflow + SNS 打造出一個「自動化 + 可重入 + 可追蹤」的雲端 ETL Pipeline。
在完成 Backfill 機制後,我們的資料管線已經具備了自動化與穩定性的基礎,也完成了淬鍊之章的所有內容。
但若要讓整個 Lakehouse 真正能在多人協作、跨部門使用的情境下安全運行,我們還需要引入一個關鍵角色 —— 資料權限治理(Data Governance)。
在下篇 「Day24 視覺之章-Lake Formation 概念篇」 中,我們將正式揭開 AWS 的資料治理核心服務:AWS Lake Formation。
[1] AWS Lambda Developer Guide
[2] AWS Glue Workflow Documentation
[3] Amazon SNS Developer Guide
[4] AWS EventBridge Scheduler
[5] Amazon S3 head_object API Reference


 iThome鐵人賽
iThome鐵人賽